




כיד הדמיון
שימוש בכלים אנליטיים בקוד פתוח לזיהוי אנומליות ופוטנציאל להונאות
מבוא
כלים אנליטיים משמשים את מבקרי הפנים בניתוח נתונים של תהליכים עסקיים, ואף משמשים את המבקר בבואו לאתר אנומליות ופוטנציאל להונאות. בדרך כלל השימוש הוא בכלים ייעודיים בתשלום, אך מלבד כלים אלו, שילוב של כלים אנליטיים בקוד פתוח יכול להעשיר את היכולות של מחלקות הביקורת משלבי איסוף הנתונים, הטיוב, ועד לשלב הניתוח והמסקנות. במאמר זה אסקור מספר כלים אנליטיים בקוד פתוח ואת היתרונות והתועלות שלהם.
הסבר על הכלים שיוזכרו בהמשך המאמר
- R – R היא שפת תכנות וסביבת עבודה המבוססת על קוד פתוח, המאפשרת ניתוח נתונים, חישובים סטטיסטיים והצגה ויזואלית עשירה מאוד. סביבת העבודה כוללת הרבה מאוד "חבילות" שבאמצעותן הכלי מאפשר ביצועים וניתוחים ברמה גבוהה.
- פייתון – שפה המשמשת למטרות כלליות ונפוצה מאוד בניתוחים אנליטיים, תצוגות נתונים גרפיות, "למידת מכונה" ועוד. בפייתון קיימות חבילות ספציפיות לניתוח נתונים מתקדם, תצוגות גרפיות ועוד, והכול במספר שורות בודדות של קוד.
- אקסל – אחת התוכנות הוותיקות והמוכרות. התוכנה כוללת מגוון של פונקציות דינמיות ותוכניות סטטיסטיות והיא כלי בסיסי לניתוח נתונים, אך כלי זה מתאים בעיקר לכמות נתונים שאינה גדולה במיוחד.
יתרונות שימוש בכלים בקוד פתוח
תוכנות בקוד פתוח כוללות תוכנות שקוד המקור שלהן נגיש וחופשי לשימוש הציבור, לעריכת שינויים והפצתם. שיטה זו של קוד פתוח מאפשרת למשתמשים לתרום באופן מתמיד וכך לשפר את התוכנות לטובת ציבור המשתמשים.
היתרונות בשימוש בכלים אנליטיים מסוג זה הם רבים, ובהם:
- עלות – התוכנות מוצעות בחינם וגם אם קיימות תוכנות ארגוניות ,(Enterprise versions) הן מתומחרות במחירים נוחים יחסית.
- גמישות – התוכנות בקוד פתוח מאפשרות שימוש ללא צורך בהתאמה מיוחדת, ללא תלות בספק תוכנה מסוים. נוסף על כך, ניתן לשלב בין מספר פתרונות קוד פתוח, וכך ליהנות מהיתרונות של כל כלי.
- חבילות (packages) – תוכנות אלו מכילות כמות רבה של קוד שכתב אחד המשתמשים בתוכנה. השימוש בחבילות אלו מקצר את משך העבודה ומייעל אותה.
- פורומים וקהילות תומכות – לתוכנות אלו יש קהל רב שמשתמש בתוכנות. בפורומים אלו דנים באתגרים שונים בשימוש בתוכנה ובמציאת פתרון אופטימלי.
- שילוב של תוכנות קוד פתוח עם תוכנות אחרות – ניתן לבצע חלקים מסוימים בתוכנה אחת ולהמשיך בתוכנה אחרת. לדוגמה, ניתן לטייב נתונים ב-R, לנתח את הנתונים, ואת הפלט להעביר לתוכנה אחרת כגון Power Bi אוTableau לצורך יצירת גרפים.
במאמר זה בחרתי דוגמאות טריוויאליות ופשוטות יחסית שסביר להניח שכל מי שעוסק בתחום מכיר, אולם המטרה שלי היא להראות שניתוחים המוצעים בתוכנות נפוצות בתשלום, ניתן לבצע במאמץ לא רב גם בתוכנות בקוד פתוח ואף לבצע ניתוחים מתקדמים יותר. כלומר ניתן לבצע ניתוחים מתקדמים ללא צורך בהתאמות שיידרשו לעיתים בכלים המובנים. להלן מובאות הדוגמאות הבאות באקסל, בפייתון וב-R:
1. אקסל
אקסל אינה תוכנה מסוג קוד פתוח אלא תוכנה שפותחה ומופצת על ידי מיקרוסופט. התוכנה כוללת יכולות רבות ובהן: טיוב נתונים, ניתוח נתונים והצגה גרפית שלהם. בחרתי את ההצגה בתוכנה זו מאחר שהיא זמינה לכולם ולטעמי המשתמשים בה לא מנצלים חלק רב מהיכולות שלה.
הבדיקה שבחרתי היא שימוש בחוק בנפורד, שנקרא על שם הפיזיקאי פרנק אלפרד בנפורד, אודות ההסתברות של הופעת ספרות בנתונים מספריים. לפי החוק, הספרה 1 היא הכי נפוצה, אחריה 2, וכך עד 9. חוק זה מסייע למצוא אנומליות באוכלוסיות שונות, כגון בתחום הרכש והמכירות, ולמעשה באין-סוף של תחומים.
בבדיקה המוצגת סקרנו חשבוניות לספקים והתפלגות הספרה הראשונה שלהם בין 1 ל-9, כאשר התפלגות שונה של הספרות הראשונות מאוכלוסיית החשבונות, לעומת ההתפלגות של הספרות לפי חוק בנפורד, עלולה להצביע על פוטנציאל לחשבוניות פיקטיביות.
ניתן לראות בגרף המצורף שהספרות לפי בנפורד ולפי החברה הנבדקת דומים. בנוסף חישבנו באקסל את Chi-square (מבחן סטטיסטי שמטרתו לבחון האם קיימת תלות סטטיסטית בין שני משתנים) שבדוגמה הספציפית הזו, והוא ייצג את ההפרש בין הערך הנצפה עבור כל ספרה לבין הערך בנוסחת בנפורד. חישוב הערך המחושב היה 9.5, ואילו הערך הקריטי לדחיית השערת האפס ברמת ביטחון של 95% אחוז היה 15.5, כך שניתן לומר שבסבירות ביטחון של 95% שלא ניתן לדחות את השערת האפס (Null Hypothesis, השערת האפס במקרה זה היא הנחת התפלגות הספרות כפי שחושבו על פי חוק בנפורד). לכן נתוני החברה הנבדקת מתנהגים בהתאם לחוק בנפורד, והמשמעות היא שלא נמצאו אינדיקטורים שמצריכים בחינה נוספת.
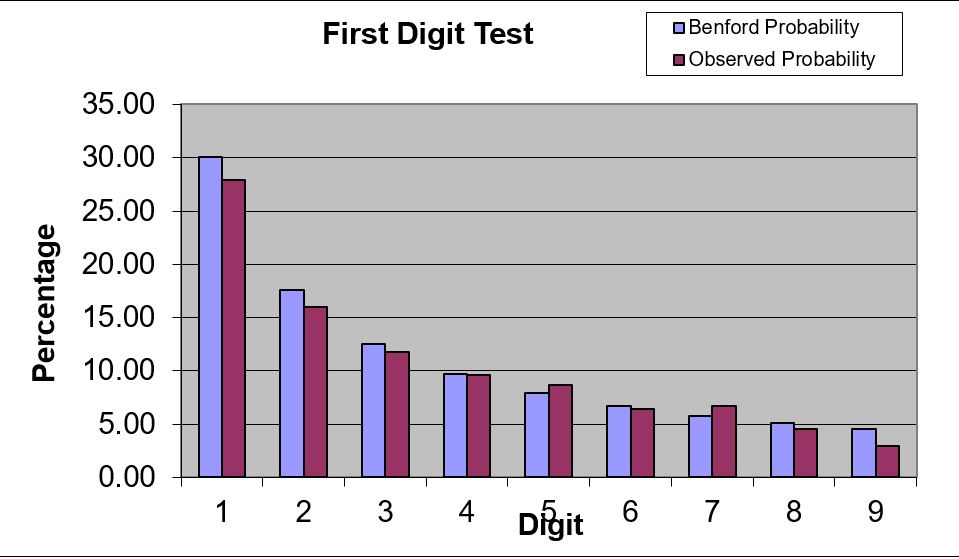
ההפרשים קטנים מאוד, ולכן ניתן לומר שהתפלגות הספרות בחברה מתפלגת בדומה להתפלגות בנפורד.
2. Python
הדוגמה שבחרתי להדגים בגרף הראשון, מראה בצורה מהירה את הפיזור של נתוני שכר בארגון גדול, כאשר השכר מחולק על פני מספר מקצועות, וכל מקצוע מוצג בBox Plot- (תרשים שבאמצעותו ניתן לבחון את החציון שמהווה את מרכז ההתפלגות, פיזור הנתונים וצורת ההתפלגות). תצוגה זו מאפשרת להשוות במבט אחד בין המקצועות השונים ולהבין את הנקודות החריגות שיש לבדוק, כך שניתן במספר שורות מצומצם של קוד לנתח אלפי עובדים ולהתמקד רק באותם עובדים חריגים. בגרף השני בחרתי להשוות את שכר העובדים בין חודש לחודש הקודם עבור כל העובדים. כל נקודה בגרף מייצגת עובד, כאשר בציר x שכר העובדים בחודש מסוים, ובציר ה-y השכר בחודש הקודם עבור אותו עובד, כך שנוצרת משוואה לינארית. הנקודות שחורגות מהמגמה הן הנקודות לבחינה מעמיקה. בשימוש בחבילה בפייתון מסוג,Plotly ניתן להפוך את הנתונים לאינטראקטיביים כך שניתן לסמן נקודה חשודה ולקבל את פרטי העובד במסך.
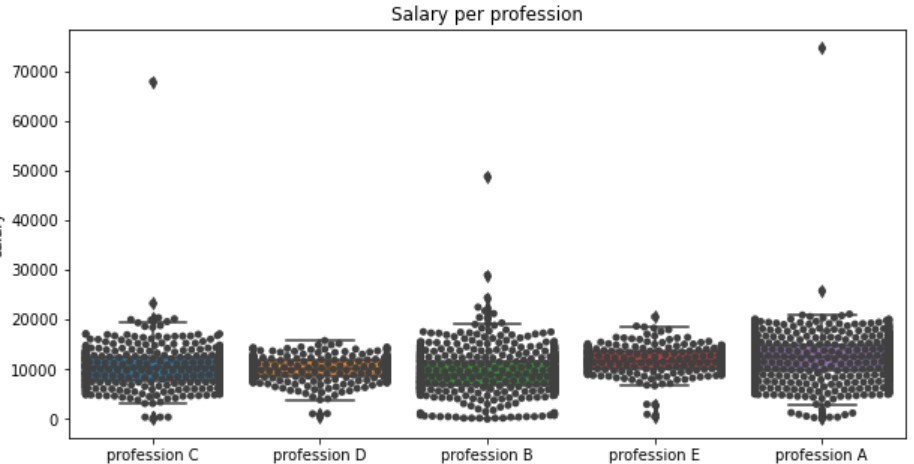
בתרשים זה ניתן לראות את פיזור השכר לפי מקצועות, כאשר כל נקודה מייצגת עובד. הנקודות שנמצאות במרחק רב משאר הנקודות מהוותOutliers (חריגים) ויש לבחון אותן.
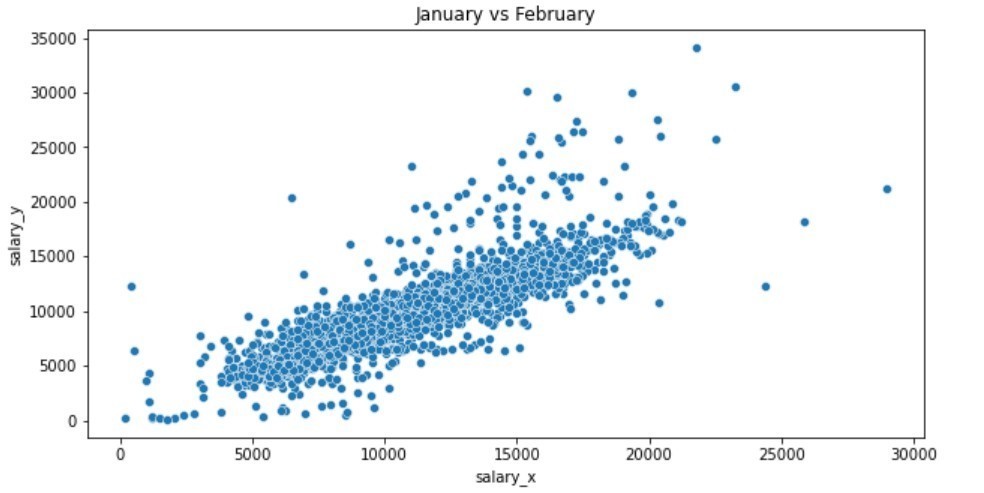 כל נקודה בגרף מציינת שכר של עובד, חודש מול חודש קודם. בהנחה ששכר העובדים לא משתנה מחודש לחודש, מתקבל גרף לינארי שבו יש לבחון את הנקודות החריגות.
כל נקודה בגרף מציינת שכר של עובד, חודש מול חודש קודם. בהנחה ששכר העובדים לא משתנה מחודש לחודש, מתקבל גרף לינארי שבו יש לבחון את הנקודות החריגות.
3. R
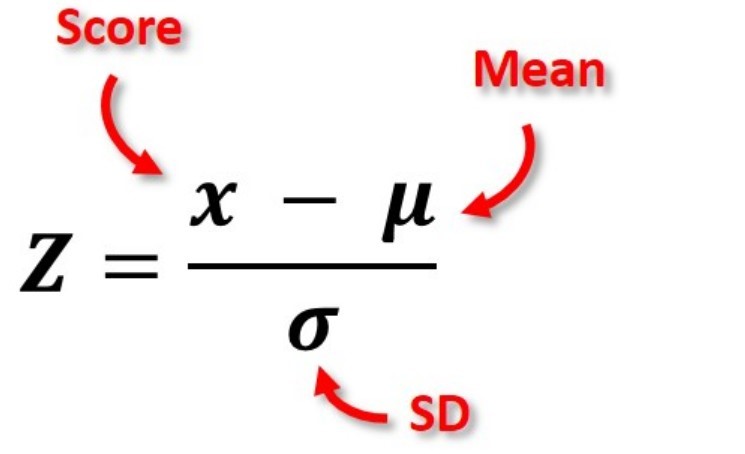
הדוגמא שבחרתי לנתח היא במסגרת ביקורת הוצאות של עובדים, במטרה לזהות אנומליות והוצאות חריגות. השתמשתי ב-z-score, מדד המציין את מרחק ערך מסוים מן הממוצע בערכים של סטיות תקן, והנוסחה שלו (כפי שמופיעה מטה) היא הערך בניכוי הממוצע חלקי סטיית התקן. מדד זה מסייע לנרמל את הנתונים ומאפשר השוואה טובה ומציאת ערכים חריגים.
טבלת העובדים כוללת 129 שורות של עובדים, מתוכן ישנם מספר עובדים שהגישו דוח הוצאות נסיעה מספר פעמים, כל דוח מיוצג על ידי שורה. צירפתי בפלט מספר שורות מתוך כל אותן שורות, והוספתי לטבלה זו עבור כל שורה באמצעות R מספר פרמטרים, כגון ממוצע, סטיית תקן, מספר שורות שמייצגות מספר דוחות הוצאה עבור כל עובד, וכן חישוב ה-Z-score. המטרה בבדיקה זו, היא ליצור ערכים מנורמלים של כל עובד ביחס לכלל דוחות ההוצאה שהגיש. בצורה זו ניתן לאתר דוחות חריגים של עובדים יחסית להוצאות של עצמם. איתור ערכים חריגים במיוחד יוכל להצביע על פוטנציאל להוצאה "מנופחת". סיננתי את הערכים הגבוהים של הפרמטר, וסינון זה העלה שתי רשומות חשודות שדורשות עיון נוסף.
פלט מתוך אוכלוסיית הוצאות הנסיעה בחברה מסוימת
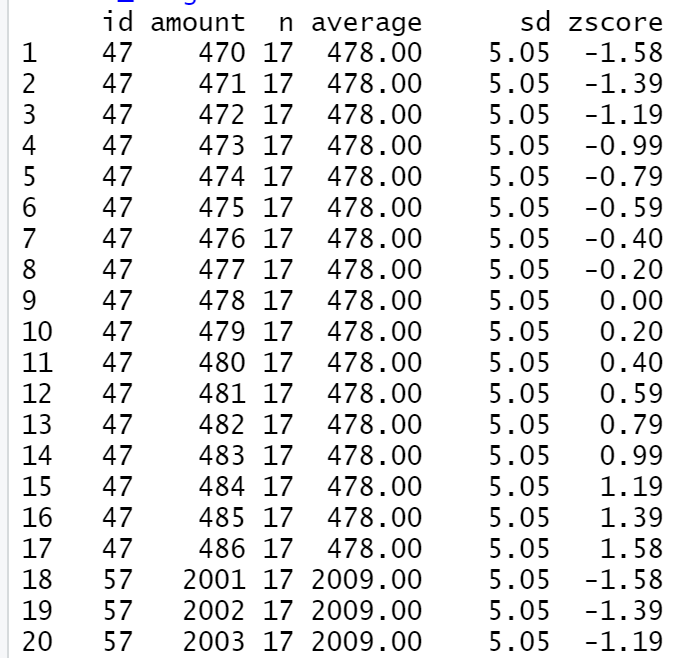
טבלה זו תורגמה ל-Z-SCORE ומאפשרת השוואה של הוצאות הנסיעה.
רשומות חשודות עם Z-score גבוה יחסית לשאר הרשומות

מתוך כל הרשומות שמייצגות דוחות של עובדים, נמצאו שני ערכים גבוהים של Z-SCORE, כלומר הוצאות גבוהות באופן מיוחד של העובד ביחס לשאר ההוצאות שלו, ולכן מהוות הוצאות חשודות המצריכות בדיקה נוספת.
לסיכום
במאמר זה בחרתי להדגים שימוש במספר תוכנות בקוד פתוח, ואיתן לזהות אנומליות ופוטנציאל להונאות. בנוסף בחרתי להשתמש בשלושה כלים לניתוח, ויכולתי בנקל להדגים כלים נוספים מסוג קוד פתוח, אך מטרתי הייתה להדגים את הרעיון והחשיבות הרבה של שימוש בכלים אלו. העבודה עם קוד פתוח מאפשרת בנייה של סקריפטים כיד הדמיון, לאור היתרונות שציינתי בתחילת המאמר. מומלץ לשלב שימוש בתוכנות קוד פתוח במחלקות הביקורת לצד התוכנות הנפוצות כיום, שילוב כזה יעשיר את יכולות מחלקות הביקורת, ככל שהשימוש בתוכנות אלו יגבר ואיתו הניסיון והידע, האפשרויות של מבקרי הפנים לביצוע ביקורת חכמה, אנליטית ואפקטיבית בתחום ניתוח הנתונים בכלל, ובזיהוי אנומליות ופוטנציאל להונאות בפרט, יתרבו ויביאו ערך רב לארגון.

